
요약
kernel fuzzing을 할 때 system call의 정보를 이용해서 진행하는 것이 일반적이다. open source의 경우에는 system call의 정보가 문서화 되어있기 때문에 활용할 수 있지만, closed source는 그렇지 않다.
즉 window의 경우 system call을 활용하고 싶어도 문서화 되어있지 않고 알려지지 않아서 fuzzing을 수행하기 어렵다. NTFuzzer는 closed source 환경에서 system call의 type을 추론하여 fuzzing에 사용하는 최초의 windows kernel fuzzer이다.
동기
Linux 커널의 경우에는 syscall이 정확하게 문서화 되어있기 때문에 kernel fuzzing에 사용할 수 있다. 하지만 windows의 경우에는 그렇지 않고, system call 규약이 자주 변경되기도 한다. windows의 변화하는 시스템콜에서 type을 추론하는 windows fuzzer는 존재하지 않는다. 대부분은 글꼴 관련 API 및 IOCTL 인터페이와 같은 부분에 초점을 맞추어 진행하거나, 사용자가 제공한 지식이나, hardness code에 의존한다.
API
M. Jurczyk, “BrokenType,” https://github.com/googleprojectzero/ BrokenType.
IOCTL fuzzer
S. Y. Kim, S. Lee, I. Yun, W. Xu, B. Lee, Y. Yun, and T. Kim, “CABFuzz: Practical concolic testing techniques for COTS operating systems,” in Proceedings of the USENIX Annual Technical Conference, 2017, pp.
689–701.
D. Oleksiuk, “Ioctl fuzzer,” https://github.com/Cr4sh/ioctlfuzzer, 2009.
논문에 제시된 NTFUZZER는 system call의 type을 자동으로 추론하는 windows kernel fuzzer이다.
핵심 아이디어는 Windows에서 system call이 대부분 문서화되지 않더라도, 알려진(API 문서화된) API 함수가 종종 내부 함수 호출 체인을 통해 해당 시스콜을 호출한다는 것이다. 이는 문서화된 인터페이스와 문서화되지 않은 인터페이스 사이의 정보 격차를 정적 분석을 통해 극복할 수 있다는 것을 의미한다. 문서화된 함수에서 문서화되지 않은 system call로 지식 전파를 통해 이를 해결했다.
추론된 system call type 정보를 사용하면 NTFUZZER는 hooking을 통해 인자의 값을 변형하여 fuzzing을 수행한다. 때문에 kAFL이나 pe-afl처럼 사용자가 hardness code를 작성할 필요가 없다.
// Syscall in kernel-mode.
NtUserRegisterWindowMessage(UNICODE_STRING* arg) {
... // Sanitize ’arg’.
unsigned short len = arg->Length;
wchar_t* buf = arg->Buffer;
if ( len & 1 ) {
LogError(...); // Does not abort.
}
else {
tmp = ((char*)buf) + len + 2;
if (tmp >= 0x7fff0000 || tmp <= buf || ... ) {
return;
}
}
... // Access ’buf’.
}
// API function in user-mode.
RegisterWindowMessage(char* s) {
UNICODE_STRING str;
str.Buffer = malloc(2 * strlen(s) + 2);
str.Length = 2 * strlen(s);
...
NtUserRegisterWindowMessage(&str);
}다음 코드는 CVE-2020-0792의 간략화 시킨것이다. NtUserRegisterWindowMessage는 UNICODE_STRING 인자를 하나 받는다.
이때 길이가 홀수인 경우 Log만 남기고 else문을 건너뛰어 버린다. 그 경우 홀수 길이와 buffer를 지정하여 안정성 검증을 우회할 수 있다.
이 예제에는 중요한 점이 몇가지 있다.
첫째로, NtUserRegisterWindowMessage의 type을 인식하지 않으면 버그를 트리거하는 것이 어렵다. Fuzzer는 시스템 호출의 입력 인자가 포인터이며 UNICODE_STRING 유형의 구조체를 가리켜야 함을 알아야 한다. type 정보를 알지 못한 채로 생성된 값은 Length 필드가 홀수이고 Buffer 필드가 잘못된 메모리 영역을 가리키는 원하는 UNICODE_STRING 구조체를 가질 가능성이 희박하다.
둘째로, 문서화되지 않은 시스템 호출은 종종 문서화된 API 함수와 관련이 있습니다. 예제에서 RegisterWindowMessage는 Microsoft Docs에서 문서화되어 있지만 NtUserRegisterWindowMessage는 그렇지 않다. 그러나 우리는 문서화된 API 함수의 알려진 유형 정보를 통해 이 시스템 호출의 유형을 추론할 수 있다.
셋째로, API 함수 수준의 퍼징은 시스템 호출을 최종적으로 호출하더라도 중요한 버그를 트리거할 수 없을 수 있다. RegisterWindowMessage 호출자는 NtUserRegisterWindowMessage에 대한 입력을 완전히 제어할 수 없다. 왜냐하면 RegisterWindowMessage는 항상 Length 필드를 짝수로 설정하기 때문이다. 결과적으로, API 함수만 퍼징하는 경우에는 시스템 호출 내의 버그가 결코 트리거되지 않을 것이다.
Windows 아키텍처
windows 10에는 1,600개 이상의 system call이 있는데 대부분 알려지지 않았다. 하지만 API는 문서화 되어있기 때문에 이 API를 정적 분석하여 system call의 type을 추론한다.
예를들어 NtCreateFile syscall을 호출하기 위해서 kernel32.dll에 있는 CreateFile API를 호출한다. NTFUZZER에서는 핵심 dll을 정적분석하여 systemcall의 인자를 분석하여 fuzzing에 사용하였다.

Overview
NTFUZZER 아키텍처
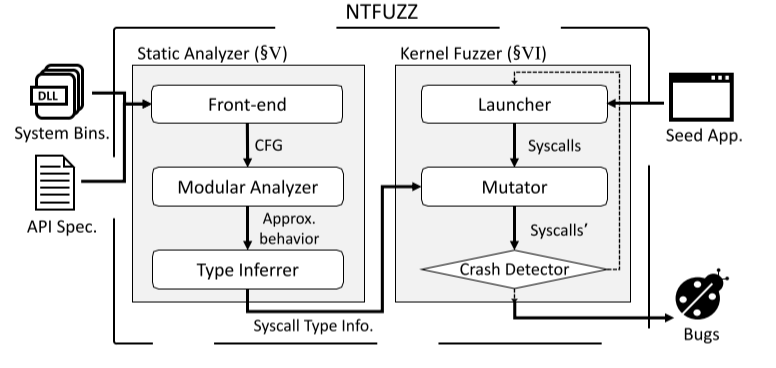
NTFUZZ는 두 가지 핵심 구성 요소인 (1) 정적 분석기와 (2) 커널 퍼저로 구성된다.
1 정적 분석기
정적 분석기는 front-end, Modular Analyer, Type Inferrer로 구성되어있다.
Front-end에서는 system binary를 IR로 변환한 다음 CFG를 만든다. 또한 API spec.에 따라 형식을 변환한다.
Modular Analyzer에서는 CFG를 탐색하고 binary에서 호출 인자를 어떤 방식으로 구성하는지 관찰한다.
Type Inferrer는 각 system call의 호출 인자의 type을 추론한다.
2 커널 퍼저
커널 퍼저는 Launcher, Mutator, Crash Detector로 구성되어있다.
Launcher는 system call hooking 및 application 실행을 한다.
Mutator는 Type Inferrer의 system call type info를 이용해 Mutation을 만든다.
Crash Detector는 Crash를 감지한다.
Modular Analysis Algorithm
NTFUZZER의 정적 분석기는 Modular analysis를 사용한다. Modular analyer는 target program을 여러개의 modules로 나누고 결과를 재조합하는 방식으로 동작한다.

NTFUZZER는 프로그램을 여러 함수로 나누고, 각 함수에 대해서 그 의미를 분석하고 요약을 정리한다. 나중에 또 다시 함수가 호출된 경우 이 요약을 이용해 분석을 최소화 시킨다.
CFG, Call Graph, APISpec을 바탕으로 리프노드에서부터 bottom-up으로 함수를 분석한다.
Modular analysis를 이용한 장점은 다음과 같다.
함수 요약을 사용했기 때문에 프로시저 사이의 동작을 분석 할 수 있고, context sensitive하게 분석이 가능하다.
또한 각 함수를 1번만 분석하기 때문에 최소의 cost만 소모한다.
하지만 caller보다 callee가 먼저 분석되어야 하기 때문에 재귀 호출이나, 간접 호출의 경우 정확하게 처리할 수 없다.

다음과 같은 실행 예시가 있다. 함수 f만 API로 문서화 되어있다.
NTFUZZER는 call graph를 만들고 left노드부터 분석한다. (h->g->f 순이라고 가정)
h를 보면 a가 b로 업데이트 된다는 정보를 얻을 수 있다.
g를 보면 상수 20과 g의 매개변수이 syscall에 사용된다.
이제 이 요약을 가지고 f를 분석한다.
line 6에서 g의 인자가 전달될 때 line 3에서 생성된 힙 객체를 사용한다. line 4~5에서 객체가 업데이트 되는 것을 바탕으로 g의 매개변수는 구조체를 가르키는 포인터임을 알 수 있다. p는 0번 offset에는 HANDLE을 가지고 +4 offset에는 int를 가지는 구조체임을 알 수 있다.
이 과정을 통해 system call의 type의 정보를 가질 수 있다.
하지만 함수 경계를 넘어 데이터 플로우를 추적 할 수 있어야 하기 때문에 실전에서 syscall 유형을 정확하게 아는것은 어렵다.
STATIC ANALYZER DESIGN
Front-End
B2R2를 이용하여 binary를 파싱하고 IR로 표현한다.
CFG의 크기를 줄이기 위해 필요 없는 노드는 삭제한다. sysenter 명령을 실행하는 system call stub함수를 식별하고 그 함수로부터 호출되는 함수까지 CFG를 역순으로 추적한다. API까지 추적했으면 멈추는데, document가 있기 때문에 분석이 무의미 하기 때문이다.
stub함수에서 호출되는 모든 함수를 S1에 포함시킨다. 다음에 S1에서 호출하는 함수를 S2로 정의한다. 마지막으로 원래 호출에서 S1∪S2 만 남기고 삭제한다.
Front-End는 또한 API spec을 파싱을 하는 동작도 한다. 여기에는 Source Anntation Language로 작성된 주석 등도 모두 포함된다.
Modular analyzer
CFG 노드를 분석하여 진행된다. 추상 상태를 이용하여 함수를 요약하는데, syscall의 인자로 전달되는 값과 함수 진입 - 종료 사이의 상태 변화를 관찰하여 수행한다.

1) 추상 도메인
도메인은 Fig. 6. 처럼 제시된다. 추상 값 V는 추상 정수, 추상 위치, 제약 조건 3가지의 집합이다.
추상 정수는 레지스터나, 메모리 cell에서 가질 수 있는 숫자 값을 의미한다. 심볼을 사용하는데 a = 0이면 구체적인, 정확한 값이고, 그렇지 않으면 symbolic을 의미한다. 심볼을 사용하기 위해 선형 표현식으로 나타낸다.
추상 위치는 잠재적인 위치를 나타낸다. Global, Stack, Heap의 경우 각 영역에 대한 offset을 표기하고 SymLoc은 symbolic pointer에 대한 offset을 나타낸다.
제약 조건은 구체적인 타입이나 symbolic type일 수 있다.
예를들어 f(0x7ffffffff000)이라는 함수가 있으면 a는 정수일 수 도 있고 포인터일 수도 있다. 이 두가지 경우를 모두 고려하기 위해 추상정수를 1 * α1 + 0처럼 표기한다. 이후 추상 위치 SymLoc(α2, 0)를 나타내고, SymTyp(α3)로 제약 조건을 생성한다. 마지막으로 이 모든 것을 포함하는 추상 값 <α1, {SymLoc(α2, 0)}, {SymTyp(α3)}>으 표기한다. 함수 분석이 되면 이 심볼들을 사용해 요약을 얻게 된다.
2) Abstract Semantics
B2R2에서 주어진 표현식을 이용해 추상 상태 S에서 평가해 추상 값 V를 반환 하게 할 것이다.
레지스터 읽기, 쓰기, 메모리 읽기 쓰기는 간단하다. 주어진 추상상태를 찾고 값을 가져오면 된다.
숫자 표현식은 범위를 확인한다. 숫자가 0인경우 NULL과 정수 상수 0을 구분할 수 없어서 안전하게 무시한다. 숫자가 데이터 section에 포함되면 global pointer로 생각할 수 있다.
이항 연산은 제약조건을 생성한다. 예를들어 두 값을 곱하는 경우를 생각해보자.

ebp에는 stack pointer가 있다고 가정한다. 일반적인 VSA에서는 ecx의 범위를 구한 뒤 ecx가 불명확하면 edi가 가질 수 있는 값을 [−∞, ∞]으로 설정하는데, 이 경우 edi가 임의의 메모리 위치를 가르키는것이 되버린다. NTFUZZER에서는 상수 offset인 경우에만 추적하고 나머지는 무시한다. 대신 esi의 위치를 edi에 설정한다.
3) Comparison against VSA
일반적인 VSA는 precisely (false positive) 하지 않는다. NTFUZZER는 soundly(False negative)를 조금 잃지만 추상위치에 대해 항상 구체적인 offset을 구할 수 있다.
Type Inferrer
1) 구조 분석
인자가 pointer가 아니면 쉽게 알 수 있다. 하지만 pointer일 경우 pointer가 가르키는 인자의 type을 알기 위해서는 memory를 검사해야한다.

구조체가 스택에 할당된 경우 특히 더 어려운데, binary level에서 구조체를 쓴것과 쓰지 않은것을 구분 할 수 없기 때문이다. 이 경우 메모리 접근 패턴을 관찰하여 해결하는데, 인접한 스택 변수가 사용되지 않은경우, 변수가 정의 없이 사용된 경우를 탐지하여 구조체로 판단한다.
2) 배열 추론
배열은 동적할당을 하는경우, API에 SAL로 명시되어있는 경우 쉽게 배열의 크기를 추론할 수 있다.
KERNEL FUZZER DESIGN
Launcher
hooking based fuzzing을 진행하며, syscall 인자를 hooking을 통해 변경한다. GUI를 쓰는 작업도 수행할 수 있다.
Mutator
구현된 mutator는 다음과 같다
int : bit flip, 산술 mutation, 경계값 ...
string : 랜덤 문자로 대체, 랜덤 문자열로 확장, 문자열을 임의로 줄임
HANDLE : HANDLE이 잘못되면 초기 조건에 많이 걸리기 때문에 건들지 않는다.
struct : 각 필드의 type을 고려하여 fuzzing
array : 크기를 알고 있으면 크기를 고려하여 변경, 아닌 경우 단일 배열로 간주
pointer : pointer와 pointer가 가르키는 값 두 개를 변경
LAZY Mutation
모든 systemcall 인자를 변경하는 것은 오히려 버그를 찾을 확률을 낮출 수 있기 때문에 확률 p를 정해 확률적으로 변이 시킨다. 또한 변이 없이 system call을 호출하고 system call 호출 횟수의 평균값을 구한뒤 mutation을 수행한다. system call 호출 횟수를 측정하여 오류처리 루틴의 영향을 줄이고 fuzzing의 공정성을 높일 수 있다.

Crash Detector
kernel fuzzing에서는 crash가 발생하면 system이 down되기 때문에 VM을 이용한다. crash가 발생하면 memeory dump를 host에게 전송한다.
